If you regularly read cognitive science or psychology blogs (or even just the lowly New York Times!), you’ve probably heard of something called the Dunning-Kruger effect. The Dunning-Kruger effect refers to the seemingly pervasive tendency of poor performers to overestimate their abilities relative to other people–and, to a lesser extent, for high performers to underestimate their abilities. The explanation for this, according to Kruger and Dunning, who first reported the effect in an extremely influential 1999 article in the Journal of Personality and Social Psychology, is that incompetent people by lack the skills they’d need in order to be able to distinguish good performers from bad performers:
…people who lack the knowledge or wisdom to perform well are often unaware of this fact. We attribute this lack of awareness to a deficit in metacognitive skill. That is, the same incompetence that leads them to make wrong choices also deprives them of the savvy necessary to recognize competence, be it their own or anyone else’s.
For reasons I’m not really clear on, the Dunning-Kruger effect seems to be experiencing something of a renaissance over the past few months; it’s everywhere in the blogosphere and media. For instance, here are just a few alleged Dunning-Krugerisms from the past few weeks:
…So what does this mean in business? Well, it’s all over the place. Even the title of Dunning and Kruger’s paper, the part about inflated self-assessments, reminds me of a truism that was pointed out by a supervisor early in my career: The best employees will invariably be the hardest on themselves in self-evaluations, while the lowest performers can be counted on to think they are doing excellent work…
…Heidi Montag and Spencer Pratt are great examples of the Dunning-Kruger effect. A whole industry of assholes are making a living off of encouraging two attractive yet untalented people they are actually genius auteurs. The bubble around them is so thick, they may never escape it. At this point, all of America (at least those who know who they are), is in on the joke ““ yet the two people in the center of this tragedy are completely unaware…
…Not so fast there — the Dunning-Kruger effect comes into play here. People in the United States do not have a high level of understanding of evolution, and this survey did not measure actual competence. I’ve found that the people most likely to declare that they have a thorough knowledge of evolution are the creationists“¦but that a brief conversation is always sufficient to discover that all they’ve really got is a confused welter of misinformation…
As you can see, the findings reported by Kruger and Dunning are often interpreted to suggest that the less competent people are, the more competent they think they are. People who perform worst at a task tend to think they’re god’s gift to said task, and the people who can actually do said task often display excessive modesty. I suspect we find this sort of explanation compelling because it appeals to our implicit just-world theories: we’d like to believe that people who obnoxiously proclaim their excellence at X, Y, and Z must really not be so very good at X, Y, and Z at all, and must be (over)compensating for some actual deficiency; it’s much less pleasant to imagine that people who go around shoving their (alleged) superiority in our faces might really be better than us at what they do.
Unfortunately, Kruger and Dunning never actually provided any support for this type of just-world view; their studies categorically didn’t show that incompetent people are more confident or arrogant than competent people. What they did show is this:
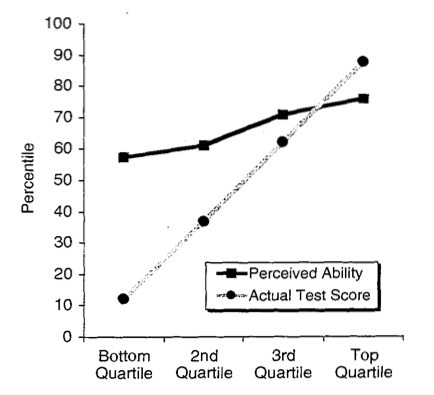
This is one of the key figures from Kruger and Dunning’s 1999 paper (and the basic effect has been replicated many times since). The critical point to note is that there’s a clear positive correlation between actual performance (gray line) and perceived performance (black line): the people in the top quartile for actual performance think they perform better than the people in the second quartile, who in turn think they perform better than the people in the third quartile, and so on. So the bias is definitively not that incompetent people think they’re better than competent people. Rather, it’s that incompetent people think they’re much better than they actually are. But they typically still don’t think they’re quite as good as people who, you know, actually are good. (It’s important to note that Dunning and Kruger never claimed to show that the unskilled think they’re better than the skilled; that’s just the way the finding is often interpreted by others.)
That said, it’s clear that there is a very large discrepancy between the way incompetent people actually perform and the way they perceive their own performance level, whereas the discrepancy is much smaller for highly competent individuals. So the big question is why. Kruger and Dunning’s explanation, as I mentioned above, is that incompetent people lack the skills they’d need in order to know they’re incompetent. For example, if you’re not very good at learning languages, it might be hard for you to tell that you’re not very good, because the very skills that you’d need in order to distinguish someone who’s good from someone who’s not are the ones you lack. If you can’t hear the distinction between two different phonemes, how could you ever know who has native-like pronunciation ability and who doesn’t? If you don’t understand very many words in another language, how can you evaluate the size of your own vocabulary in relation to other people’s?
This appeal to people’s meta-cognitive abilities (i.e., their knowledge about their knowledge) has some intuitive plausibility, and Kruger, Dunning and their colleagues have provided quite a bit of evidence for it over the past decade. That said, it’s by no means the only explanation around; over the past few years, a fairly sizeable literature criticizing or extending Kruger and Dunning’s work has developed. I’ll mention just three plausible (and mutually compatible) alternative accounts people have proposed (but there are others!)
1. Regression toward the mean. Probably the most common criticism of the Dunning-Kruger effect is that it simply reflects regression to the mean–that is, it’s a statistical artifact. Regression to the mean refers to the fact that any time you select a group of individuals based on some criterion, and then measure the standing of those individuals on some other dimension, performance levels will tend to shift (or regress) toward the mean level. It’s a notoriously underappreciated problem, and probably explains many, many phenomena that people have tried to interpret substantively. For instance, in placebo-controlled clinical trials of SSRIs, depressed people tend to get better in both the drug and placebo conditions. Some of this is undoubtedly due to the placebo effect, but much of it is probably also due to what’s often referred to as “natural history”. Depression, like most things, tends to be cyclical: people get better or worse better over time, often for no apparent rhyme or reason. But since people tend to seek help (and sign up for drug trials) primarily when they’re doing particularly badly, it follows that most people would get better to some extent even without any treatment. That’s regression to the mean (the Wikipedia entry has other nice examples–for example, the famous Sports Illustrated Cover Jinx).
In the context of the Dunning-Kruger effect, the argument is that incompetent people simply regress toward the mean when you ask them to evaluate their own performance. Since perceived performance is influenced not only by actual performance, but also by many other factors (e.g., one’s personality, meta-cognitive ability, measurement error, etc.), it follows that, on average, people with extreme levels of actual performance won’t be quite as extreme in terms of their perception of their performance. So, much of the Dunning-Kruger effect arguably doesn’t need to be explained at all, and in fact, it would be quite surprising if you didn’t see a pattern of results that looks at least somewhat like the figure above.
2. Regression to the mean plus better-than-average. Having said that, it’s clear that regression to the mean can’t explain everything about the Dunning-Kruger effect. One problem is that it doesn’t explain why the effect is greater at the low end than at the high end. That is, incompetent people tend to overestimate their performance to a much greater extent than competent people underestimate their performance. This asymmetry can’t be explained solely by regression to the mean. It can, however, be explained by a combination of RTM and a “better-than-average” (or self-enhancement) heuristic which says that, in general, most people have a tendency to view themselves excessively positively. This two-pronged explanation was proposed by Krueger and Mueller in a 2002 study (note that Krueger and Kruger are different people!), who argued that poor performers suffer from a double whammy: not only do their perceptions of their own performance regress toward the mean, but those perceptions are also further inflated by the self-enhancement bias. In contrast, for high performers, these two effects largely balance each other out: regression to the mean causes high performers to underestimate their performance, but to some extent that underestimation is offset by the self-enhancement bias. As a result, it looks as though high performers make more accurate judgments than low performers, when in reality the high performers are just lucky to be where they are in the distribution.
3. The instrumental role of task difficulty. Consistent with the notion that the Dunning-Kruger effect is at least partly a statistical artifact, some studies have shown that the asymmetry reported by Kruger and Dunning (i.e., the smaller discrepancy for high performers than for low performers) actually goes away, and even reverses, when the ability tests given to participants are very difficult. For instance, Burson and colleagues (2006), writing in JPSP, showed that when University of Chicago undergraduates were asked moderately difficult trivia questions about their university, the subjects who performed best were just as poorly calibrated as the people who performed worst, in the sense that their estimates of how well they did relative to other people were wildly inaccurate. Here’s what that looks like:

Notice that this finding wasn’t anomalous with respect to the Kruger and Dunning findings; when participants were given easier trivia (the diamond-studded line), Burson et al observed the standard pattern, with poor performers seemingly showing worse calibration. Simply knocking about 10% off the accuracy rate on the trivia questions was enough to induce a large shift in the relative mismatch between perceptions of ability and actual ability. Burson et al then went on to replicate this pattern in two additional studies involving a number of different judgments and tasks, so this result isn’t specific to trivia questions. In fact, in the later studies, Burson et al showed that when the task was really difficult, poor performers were actually considerably better calibrated than high performers.
Looking at the figure above, it’s not hard to see why this would be. Since the slope of the line tends to be pretty constant in these types of experiments, any change in mean performance levels (i.e., a shift in intercept on the y-axis) will necessarily result in a larger difference between actual and perceived performance at the high end. Conversely, if you raise the line, you maximize the difference between actual and perceived performance at the lower end.
To get an intuitive sense of what’s happening here, just think of it this way: if you’re performing a very difficult task, you’re probably going to find the experience subjectively demanding even if you’re at the high end relative to other people. Since people’s judgments about their own relative standing depends to a substantial extent on their subjective perception of their own performance (i.e., you use your sense of how easy a task was as a proxy of how good you must be at it), high performers are going to end up systematically underestimating how well they did. When a task is difficult, most people assume they must have done relatively poorly compared to other people. Conversely, when a task is relatively easy (and the tasks Dunning and Kruger studied were on the easier side), most people assume they must be pretty good compared to others. As a result, it’s going to look like the people who perform well are well-calibrated when the task is easy and poorly-calibrated when the task is difficult; less competent people are going to show exactly the opposite pattern. And note that this doesn’t require us to assume any relationship between actual performance and perceived performance. You would expect to get the Dunning-Kruger effect for easy tasks even if there was exactly zero correlation between how good people actually are at something and how good they think they are.
Here’s how Burson et al summarized their findings:
Our studies replicate, eliminate, or reverse the association between task performance and judgment accuracy reported by Kruger and Dunning (1999) as a function of task difficulty. On easy tasks, where there is a positive bias, the best performers are also the most accurate in estimating their standing, but on difficult tasks, where there is a negative bias, the worst performers are the most accurate. This pattern is consistent with a combination of noisy estimates and overall bias, with no need to invoke differences in metacognitive abilities. In this regard, our findings support Krueger and Mueller’s (2002) reinterpretation of Kruger and Dunning’s (1999) findings. An association between task-related skills and metacognitive insight may indeed exist, and later we offer some suggestions for ways to test for it. However, our analyses indicate that the primary drivers of errors in judging relative standing are general inaccuracy and overall biases tied to task difficulty. Thus, it is important to know more about those sources of error in order to better understand and ameliorate them.
What should we conclude from these (and other) studies? I think the jury’s still out to some extent, but at minimum, I think it’s clear that much of the Dunning-Kruger effect reflects either statistical artifact (regression to the mean), or much more general cognitive biases (the tendency to self-enhance and/or to use one’s subjective experience as a guide to one’s standing in relation to others). This doesn’t mean that the meta-cognitive explanation preferred by Dunning, Kruger and colleagues can’t hold in some situations; it very well may be that in some cases, and to some extent, people’s lack of skill is really what prevents them from accurately determining their standing in relation to others. But I think our default position should be to prefer the alternative explanations I’ve discussed above, because they’re (a) simpler, (b) more general (they explain lots of other phenomena), and (c) necessary (frankly, it’d be amazing if regression to the mean didn’t explain at least part of the effect!).
We should also try to be aware of another very powerful cognitive bias whenever we use the Dunning-Kruger effect to explain the people or situations around us–namely, confirmation bias. If you believe that incompetent people don’t know enough to know they’re incompetent, it’s not hard to find anecdotal evidence for that; after all, we all know people who are both arrogant and not very good at what they do. But if you stop to look for it, it’s probably also not hard to find disconfirming evidence. After all, there are clearly plenty of people who are good at what they do, but not nearly as good as they think they are (i.e., they’re above average, and still totally miscalibrated in the positive direction). Just like there are plenty of people who are lousy at what they do and recognize their limitations (e.g., I don’t need to be a great runner in order to be able to tell that I’m not a great runner–I’m perfectly well aware that I have terrible endurance, precisely because I can’t finish runs that most other runners find trivial!). But the plural of anecdote is not data, and the data appear to be equivocal. Next time you’re inclined to chalk your obnoxious co-worker’s delusions of grandeur down to the Dunning-Kruger effect, consider the possibility that your co-worker’s simply a jerk–no meta-cognitive incompetence necessary.
![]() Kruger J, & Dunning D (1999). Unskilled and unaware of it: how difficulties in recognizing one’s own incompetence lead to inflated self-assessments. Journal of personality and social psychology, 77 (6), 1121-34 PMID: 10626367
Kruger J, & Dunning D (1999). Unskilled and unaware of it: how difficulties in recognizing one’s own incompetence lead to inflated self-assessments. Journal of personality and social psychology, 77 (6), 1121-34 PMID: 10626367
Krueger J, & Mueller RA (2002). Unskilled, unaware, or both? The better-than-average heuristic and statistical regression predict errors in estimates of own performance. Journal of personality and social psychology, 82 (2), 180-8 PMID: 11831408
Burson KA, Larrick RP, & Klayman J (2006). Skilled or unskilled, but still unaware of it: how perceptions of difficulty drive miscalibration in relative comparisons. Journal of personality and social psychology, 90 (1), 60-77 PMID: 16448310
